
On October 20, 2025, AWS (Amazon Web Services) experienced a significant outage that took down thousands of services worldwide. Snapchat, Venmo, Robinhood, Roblox, Fortnite, Ring, and Alexa all went dark because of the AWS outage, leaving millions of users unable to access critical services and applications.
At Tech Reformers, an AWS Advanced Services Partner and Authorized Training Provider, we were busy working with state and local agencies, K-12 schools, and businesses. During an outage like this, our communication channels start “ringing.” People were worried. They depend on services that run on AWS, and if AWS has problems, their work stops.
So let’s break down what happened, why it matters, and what you can do to be prepared.
What Caused the AWS Outage?
The trouble started at 3:11 AM ET in AWS’s us-east-1 region (Northern Virginia). Multiple services began showing higher error rates and increased latency. By 5:01 AM, AWS engineers identified the culprit: DNS resolution issues affecting the DynamoDB API endpoints. That is, the managed database system lost meaningful connectivity.
Understanding DNS
DNS (Domain Name System) deserves some explanation because it’s at the heart of this outage. DNS is essentially the internet’s address book—it translates human-readable names (like “dynamodb.us-east-1.amazonaws.com”) into the IP addresses that computers use to connect.
Here’s the critical part: DNS isn’t controlled by any single company. It’s a distributed service run by independent organizations and agencies worldwide. These DNS servers are deployed worldwide and need to be continually refreshed with updated information. When DNS breaks—as it did in this case—applications can’t find the services they need to connect to, even if those services are running perfectly fine.
In this case, DynamoDB—a core database service many applications depend on—became unreachable because DNS couldn’t resolve its endpoints. The problem required manual interventions to bypass faulty network components. Complete recovery was achieved by 1 PM ET, though some services experienced lingering slowness into the evening.
The AWS us-east-1 Outage Factor
Here’s what makes this outage particularly significant: us-east-1 is AWS’s largest region (and its first). It started in 2006, running the first three services—SQS, S3, and EC2. Perhaps because of this history, many AWS global services depend on us-east-1 for critical functions.
When us-east-1 has problems, workloads around the world can be affected even if their own regional infrastructure is running perfectly.
Services with Known us-east-1 Dependencies
Several AWS services have dependencies on us-east-1:
- IAM and IAM Identify Center – Authentication and access management
- DynamoDB Global Tables – Cross-region database replication and coordination
- Amazon CloudFront – CDN (Content Delivery Network)
Sometimes you can’t avoid these dependencies. Instead, you need to build resilience around them.
Who Was Actually Affected?
Here’s what we’re hearing from our customers: their own infrastructure on AWS was fine. They were affected because services they depend on went down—Slack stopped working during critical meetings, payment systems couldn’t process transactions, and communication tools went silent. But they’re worried that next time, they could be affected.
The outage hit:
- Financial Services: Robinhood and Coinbase couldn’t process transactions
- E-commerce: Amazon.com itself went down, along with McDonald’s and Starbucks apps
- Transportation: United Airlines and Delta reported delays
- Government Services: Medicare’s enrollment portal stopped working
- Collaboration Tools: Slack and other productivity apps slowed to a crawl
- Gaming: Roblox, Fortnite, and Pokémon GO became unplayable
You can joke about some of these: Aren’t delays the norm from United and Delta? Well, did the gamers have to get to work? Maybe crypto- and day traders profited from holding anyway. But the outage is serious business.
For schools managing daily operations, agencies serving citizens, and businesses running critical workflows, these outages create real problems. When your collaboration tools go down, work stops. When your payment processor goes offline, revenue stops. When your communication systems fail, you can’t reach the people you need to reach.
Many of our customers are now asking: “What can we do about this? We’re vulnerable.”
That’s a fair question. Let’s talk about it.
Building Resilience: What You Can Actually Control
If you’re using SaaS applications that run on AWS, you have limited control over their infrastructure decisions. But you do control your infrastructure:
1. Deploy Multi-Region Architecture
Architect critical workloads to run in at least two geographically separated regions. Use Route 53 health checks and automatic failover to redirect traffic when problems occur.
Example configuration: Deploy your primary workload in us-west-2 (Oregon) and maintain a secondary deployment in us-west-1 (N. California). This geographic separation means different power grids, different network infrastructure, and reduced risk of correlated failures.
This isn’t necessary for everything. Focus on mission-critical workloads first – student information systems, file access, and business systems.
Avoid us-east-1 where possible.
2. Implement Standby Systems
Here’s where we need to talk about money because this is where organizations often hesitate.
Backup and Restore: Cheapest option, but leaves you vulnerable during outages. Recovery takes hours or days. Cost: ~1-2% of primary infrastructure.
Pilot-Light: Set up in another region, not just a backup. The infrastructure is not running but up-to-date and ready to be turned on. Recovery takes minutes to hours. Cost: ~5-10% of primary infrastructure.
Warm Standby (scaled-down infrastructure ready to scale up): Middle ground. You run minimal infrastructure in a secondary region that can quickly scale when needed. Recovery takes minutes. Cost: 20-30% additional.
Multi-site Active/Active (production-scale infrastructure in multiple regions): Most expensive, fastest recovery. Traffic is actively distributed across regions. Recovery is essentially instant. Cost: Can double your infrastructure spending.
The Real Question: What does downtime cost you? AWS itself offers an excellent solution for cross-region replication: AWS Elastic Disaster Recovery. AWS offers four main disaster recovery (DR) strategies to create backups that remain available during disasters. Each strategy has a progressively higher cost and complexity, but lower recovery times.
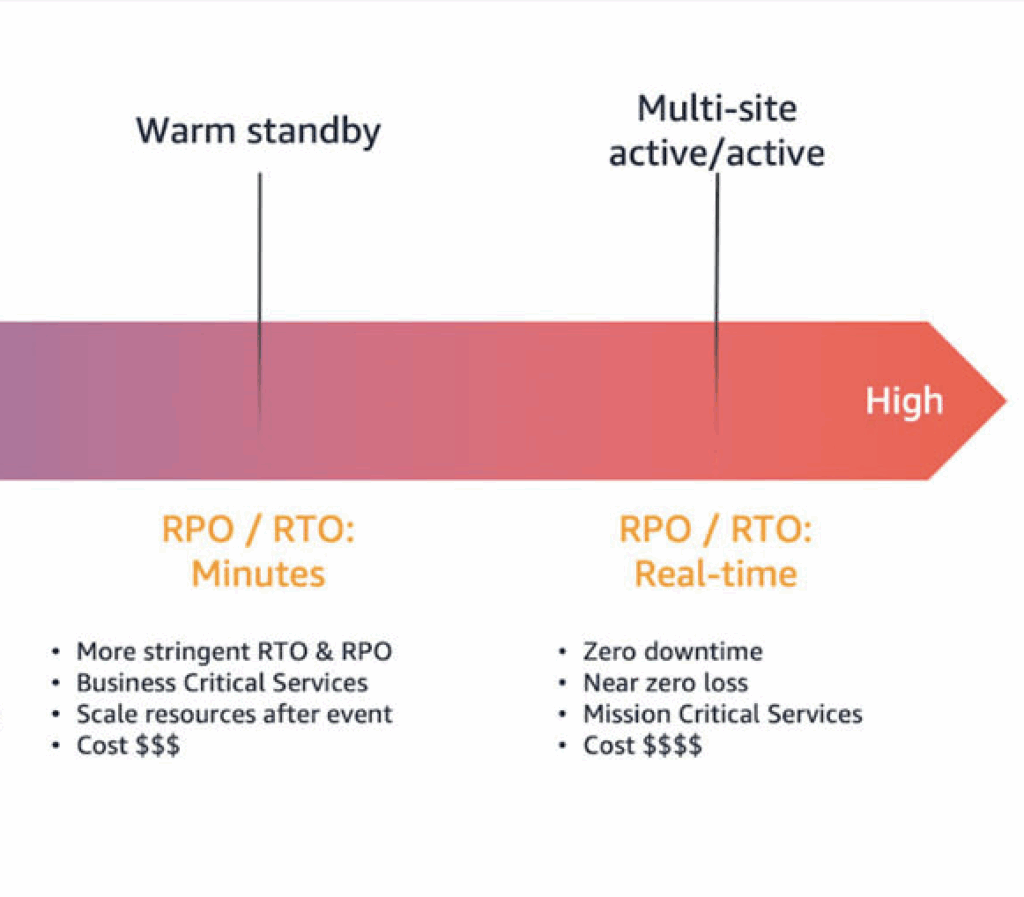
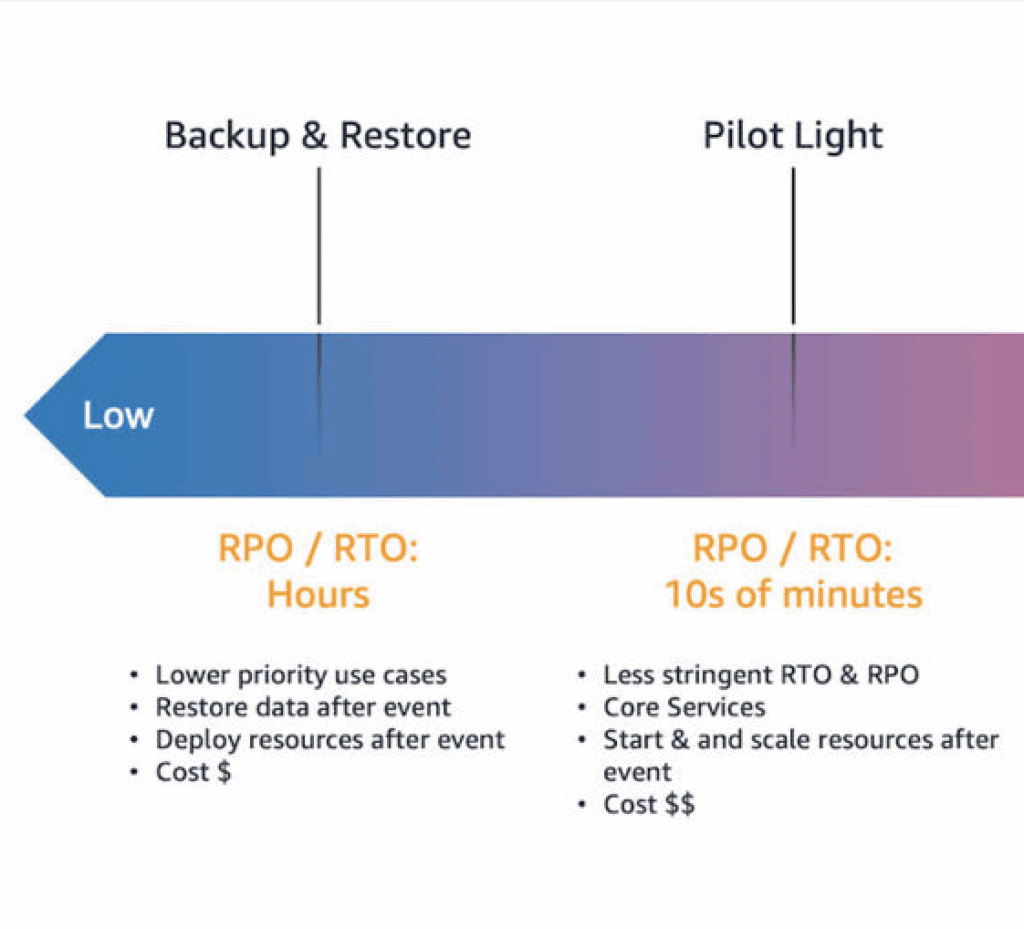
For school districts facing deadlines, being down for three hours might mean missed deadlines and frustrated families. For a government agency processing critical permits, six hours of downtime could mean compliance violations. For businesses, money is lost when there are no orders. That’s the calculation you need to make.
We help our clients figure out which workloads justify the extra cost. Not everything needs standby, but your most critical systems probably do.
3. Build Resilience Around Dependencies You Can’t Avoid
You may not eliminate dependencies on services like IAM or CloudFront. But you can reduce your exposure:
Use regional service endpoints: Where AWS offers regional alternatives, use them. Not everything needs to route through global services.
Add an alternative to the Disaster Strategy: Something is better than nothing or errors. Have local or simplified versions of a working architecture.
4. Have Backup Communication Channels
This applies to everyone, whether or not you run AWS infrastructure. When your primary collaboration tools fail, how do you communicate?
Build redundancy into communications:
- If Slack/Teams goes down, can your team switch to something else?
- If your primary email provider fails, do you have phone trees in place?
- Can you reach critical stakeholders through multiple channels?
This sounds basic, but we’ve seen organizations grind to a halt when their primary communication tool goes offline, with no backup plan.
5. Diversify Your Vendors
If possible, don’t put all your critical services on platforms that run on the same cloud provider or ecosystem. This isn’t always feasible, but where you have choices:
- Use collaboration tools from different providers
- Consider email/collaboration and data center infrastructure that run on different ecosystems
- As they say, don’t have all your eggs in one basket
The challenge: many of the best services run on AWS because it’s the largest, most reliable platform.
6. Document and Test Your Workarounds
When services you depend on go down, what’s your plan?
Create documented workarounds:
- If Teams fails, here’s how we switch to something else…
- If our file server is down, here’s our process…
- If our scheduling system fails, here’s our backup approach…
More importantly, test these workarounds—schedule drills. Time them. Make sure your team knows what to do before the emergency happens.
7. Practice Chaos Engineering—But Start with Drills First
Chaos engineering means intentionally breaking things to see how your systems respond. It’s valuable, but you need to walk before you run.
Phase 1: Scheduled Recovery Drills
Run planned failover exercises during maintenance windows. Your team knows it’s coming, they follow the runbook, and you measure how long it takes. Do this until recovery becomes routine.
Phase 2: Unannounced Drills with Random Timing
Once your team can execute recovery smoothly, start adding surprise elements—schedule drills at random times during business hours. Don’t tell the on-call person it’s coming. See if they can follow the runbook under pressure.
Phase 3: Fault Injection in Production
Only after you’ve mastered phases 1 and 2 should you consider using AWS Fault Injection Simulator (FIS) to inject random failures into production systems. Test things like:
- Regional connectivity failures
- Database unavailability
- API throttling scenarios
- DNS resolution failures
The key is randomness. Real failures don’t happen during convenient maintenance windows. They happen at 3 AM or during your busiest hours. Your systems need to handle that.
Preparing for the Next AWS Outage: Action Steps
Document what happened during this outage if it affected you:
- Which services did your organization rely on that went down?
- How long were you unable to work effectively?
- What was the business impact—missed deadlines, lost productivity, frustrated users?
- What workarounds did people improvise?
- What dependencies did you discover that you didn’t know existed?
Identify your critical dependencies:
Make a list of the services your organization absolutely needs to function. For each one, find out:
- Is it SaaS (managed service) or Cloud infrastructure you control?
- Does it have built-in redundancy?
- What’s their uptime SLA?
- What’s your backup plan if it fails?
AWS Disaster Recovery
AWS is still the best cloud platform for most workloads despite this AWS outage. This outage doesn’t change that. But it reminds us that no system is immune to failure, and dependencies we don’t even think about can bring down services we rely on.
The question isn’t whether another outage will happen—it’s whether you’ll be ready when it does. Be prepared with an AWS disaster recovery plan.
How Tech Reformers Can Help
We’ve worked with schools, agencies, and businesses to build resilient AWS architectures and prepare for disruptions like this one. Our team includes certified AWS Architects and Engineers, as well as AWS Authorized Instructors, all with deep expertise across compute, storage, networking, security, and disaster recovery.
As an AWS Advanced Services Partner and Authorized Training Provider, we offer:
AWS Well-Architected Reviews: We assess your infrastructure against AWS best practices, with a specific focus on reliability and operational excellence. Where are your single points of failure? What’s your actual recovery capability? We’ll tell you.
Disaster Recovery Planning: We help you design and implement multi-region strategies based on realistic requirements and budget constraints. We’ll help you figure out which workloads need hot standby and which don’t.
Resilience Testing Workshops: Hands-on training for your teams on failover procedures, incident response, and building resilient architectures. We’ll help you design and run your first recovery drills.
AWS Training and Certification: Official AWS courses delivered by authorized instructors. Solutions Architect, SysOps Administrator, DevOps Engineer, Security Specialty—we teach them all, both virtual and in-person.
Consulting Services: We work with you on AWS implementations, migration planning, security architecture, and ongoing optimization. Many of our solutions are available on AWS Marketplace.
Ready to avoid an AWS outage and build more resilience into your organization? Contact us for a consultation. Whether you run your own AWS infrastructure or depend on services that do, we can help you prepare for the next disruption.
Additional Resources
Contact Tech Reformers
Phone: +1 (206) 401-5530
Email: info@techreformers.com
Website: https://techreformers.com

{kind=link}