What Amazon Bedrock AgentCore Payments Means for Your AWS Career
The line between “AI assistant” and “autonomous business operator” just got a lot thinner. Amazon Bedrock AgentCore has entered preview with managed payment capabilities that allow AI agents to independently purchase access to APIs, MCP servers, web content, and other agents. Built in collaboration with Coinbase and Stripe (press releases), this capability addresses one of the biggest friction points in agentic AI architectures: the messy, custom-built billing and credential plumbing that teams previously had to build themselves. For AWS practitioners, certification candidates, and enterprise architects, this is not just a product update, it is a signal of where cloud architecture is heading. Understanding it now puts you ahead of the curve on both the exam and in the field.
What Is Amazon Bedrock AgentCore and Why Do Payments Matter?
Amazon Bedrock AgentCore is AWS’s managed runtime environment for deploying, running, and orchestrating AI agents at scale. Until now, when an agent needed to call a paid external API or access a licensed data source, a human or a custom middleware system had to handle the billing side of that transaction. The new payments capability changes that by giving agents a governed, managed way to transact autonomously. Think of it as giving your AI agent a corporate credit card with built-in controls This removes what AWS calls “undifferentiated heavy lifting,” meaning teams no longer need to engineer custom billing flows just to make their agents functional in the real world.
How This Changes Agentic Architecture on AWS
Agentic AI design has always involved four core concerns: reasoning, tool use, memory, and action. Payments now become a first-class “action” type within that framework. Previously, cost and access management for external services was a design blocker that pushed complexity back onto developers. With managed payments baked into AgentCore, architects can design agents that are truly end-to-end autonomous within defined guardrails. The MCP (Model Context Protocol) server integration point is particularly important, as MCP is fast becoming a standard interface for tool-enabled agents.
A Real-World Scenario: The Autonomous Research Agent
Imagine a pharmaceutical company building a competitive intelligence agent using Amazon Bedrock. The agent’s job is to monitor scientific literature, query licensed research databases, and summarize findings daily. Previously, whenever the agent needed to access a paid PubMed API tier or a licensed data feed, a developer had to manually provision credentials and billing accounts. With AgentCore payments, the agent can autonomously request and pay for access mid-task using pre-approved spending parameters. A Solutions Architect designing this system now needs to think about agent spend policies, Bedrock Guardrails, IAM roles scoped to payment actions, audit logging via AWS CloudTrail, and integration with AWS Cost Explorer for visibility. This is exactly the kind of multi-service, real-world scenario that shows up in professional-level certification scenarios.
What Enterprise Teams Should Be Evaluating Right Now
For enterprise cloud teams, the arrival of autonomous-agent payments raises important governance questions that require answers before production deployment. Who owns the spending policy for an agent? How are payment credentials rotated and secured? What happens when an agent hits a spending threshold mid-task? These are architectural and operational requirements that need to be built into any agentic system design. AWS’s partnership with Coinbase and Stripe suggests that both traditional web transaction and blockchain-based payment rails are in scope, which broadens the integration surface considerably. Forward-thinking cloud teams should be piloting this in preview now, documenting their governance patterns, and building internal runbooks.
Next Steps for AgentCore Payments
Amazon Bedrock AgentCore payments (documentation) is not just a feature announcement, it is a preview of what enterprise AI architecture looks like in 2026 and beyond. AI agents that can reason, act, and now transact autonomously represent a fundamental shift in how cloud solutions are designed and governed. Whether you are studying for your next AWS certification or leading a cloud transformation at scale, understanding agentic architecture is no longer optional. At TechReformers, we bring the official AWS curriculum to life with real-world context, hands-on labs, and practitioner-level demos that connect announcements like this one to what actually shows up in your exam and your job. Visit us at https://techreformers.com to explore our upcoming AI and generative AI training offerings and get ahead of where AWS is going next. 🚀
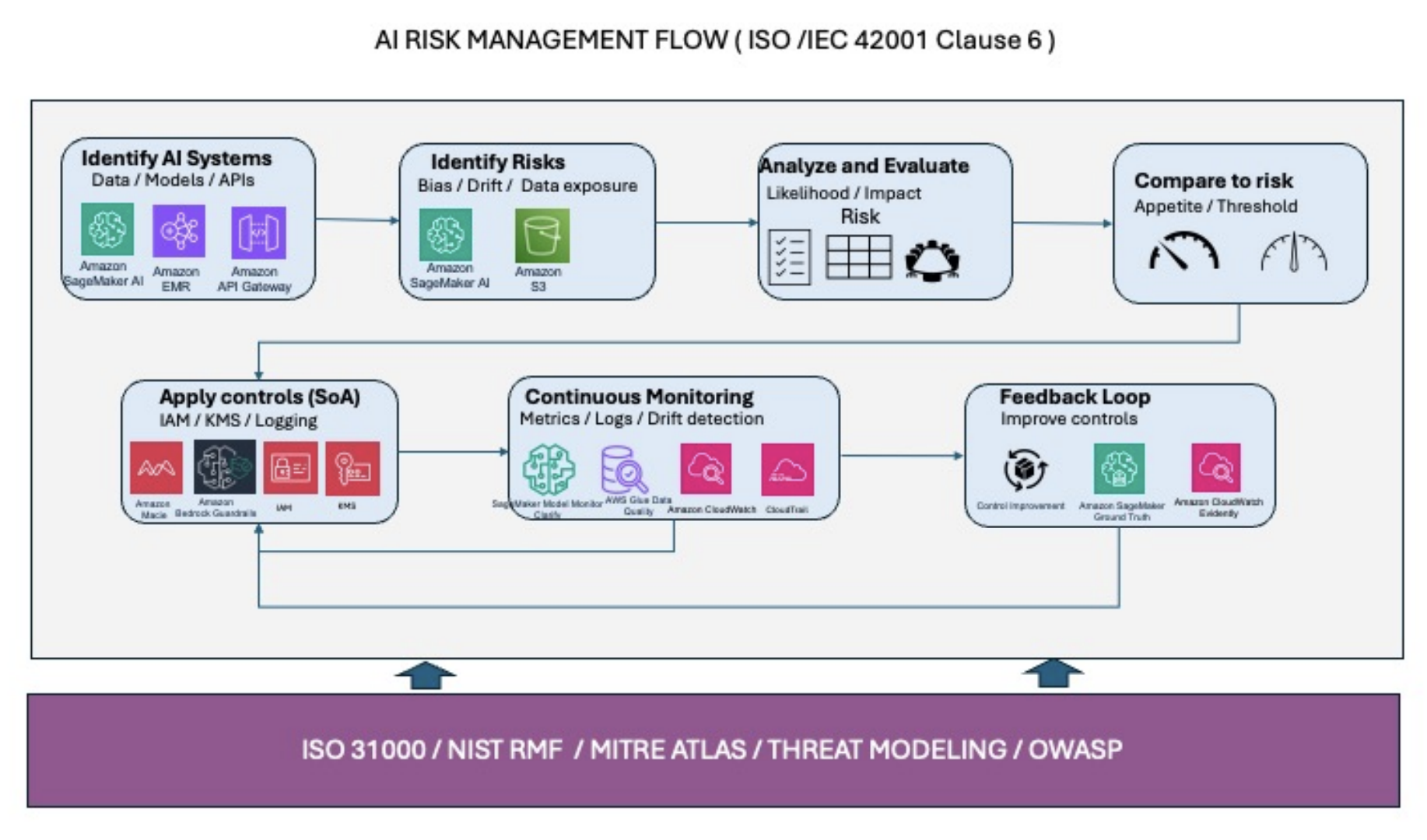
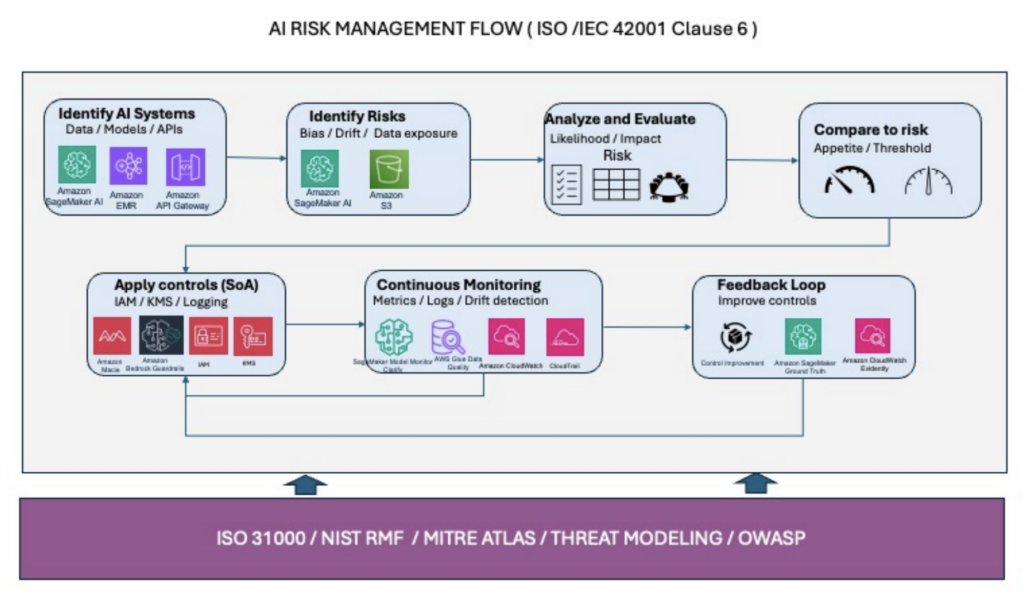
Artificial Intelligence (AI), Generative AI, and Agentic AI do not fit within historical IT in enterprise governance and compliance strategy. In present-day operational reality, there is an urgent need for governance frameworks that organizations can implement to address the risks posed by these technologies. To meet these challenges, AWS has released its AI compliance guide, “Implementing ISO/IEC 42001:2023 AI Management Systems (AIMS) on AWS” (PDF).
The May 2016 guide gives cloud teams a structured, practical resource for building an Artificial Intelligence Management System (AIMS) on AWS. This isn’t just a document for legal and compliance departments, but rather a hands-on reference that architects, security engineers, and AI developers can use to align their workloads with globally recognized standards. It specifically outlines what services to use and how to use them to meet compliance. As generative and agentic AI adoption accelerates, understanding this framework is now a core professional competency. For certification candidates and practitioners alike, this guide marks a meaningful milestone in AWS’s formalization of AI guidance in the cloud.
A Shared Responsibility
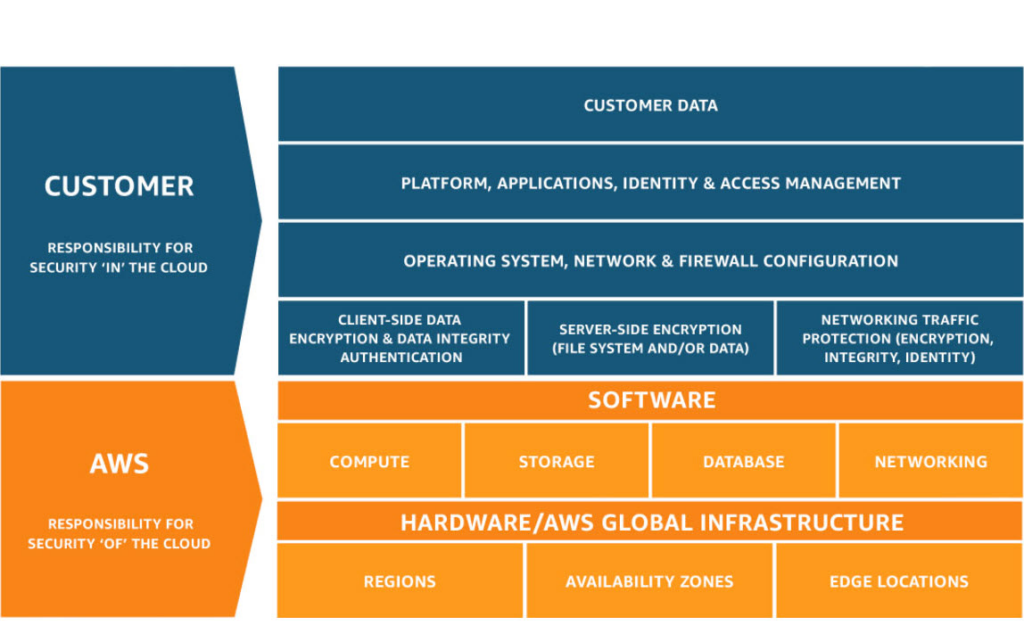
Remember that when running your AI workloads in the cloud, you adhere to the shared responsibility model. AWS states:
AI Security and AI Compliance are a shared responsibility between AWS and the customer. This shared model can help relieve the customer’s operational burden as AWS operates, manages and controls the components from the host operating system and virtualization layer down to the physical security of the facilities in which the service operates. The customer assumes responsibility and management of the guest operating system (including updates and security patches), other associated application software as well as the configuration of the AWS provided security group firewall. Customers should carefully consider the services they choose as their responsibilities vary depending on the services used, the integration of those services into their IT environment, and applicable laws and regulations. The nature of this shared responsibility also provides the flexibility and customer control that permits the deployment. As shown in the chart below, this differentiation of responsibility is commonly referred to as Security “of” the Cloud versus Security “in” the Cloud.
What Is ISO/IEC 42001:2023?
ISO/IEC 42001:2023 is the first international standard specifically designed for AI management systems, published by the International Organization for Standardization. It establishes requirements for organizations to responsibly develop, deploy, and manage AI. It covers everything from risk assessment and transparency to human oversight and continual improvement. Think of it as the AI equivalent of ISO 27001 for information security — a structured management system approach rather than a checklist. For organizations operating in regulated industries such as finance, healthcare, or government, aligning with this standard is rapidly becoming a contractual and regulatory expectation.
What the AWS AI Compliance Guide Actually Covers
The AWS ISO/IEC 42001:2023 guide provides service-level mappings showing how AWS tools and services support specific clauses in the standard. It covers areas including AI risk management, data governance, model transparency, security controls, and organizational accountability structures. Key AWS services referenced in this context include Amazon Bedrock, Amazon SageMaker, AWS CloudTrail, AWS Config, and AWS Security Hub, services that certification candidates will recognize from multiple exam domains. The guide also offers implementation guidance for teams to assess their current state and identify gaps before pursuing formal certification or audit readiness. For cloud professionals, this is the bridge between theoretical AI governance and tangible AWS architecture decisions.
AWS Training and Certification Domains and Exams
🎓 This guide is relevant across several AWS certification tracks, and candidates should treat it as supplemental reading material:
The AWS Certified AI Practitioner exam covers responsible AI, governance, and the operational aspects of AI workloads. This guide maps almost perfectly to those objectives. The AWS Certified Security Specialty exam tests deep knowledge of compliance frameworks, audit readiness, and how AWS services support regulatory requirements, all of which appear in this guide. The AWS Certified Solutions Architect – Professional exam challenges candidates on governance at scale, multi-account compliance strategies, and the design of systems for risk. Even candidates pursuing the AWS Certified Machine Learning Engineer Associate will benefit from understanding how governance wraps around the ML lifecycle. Familiarity with standards like ISO/IEC 42001 increasingly differentiates senior-level candidates from those with only technical depth.
Building a Compliant Generative AI Platform
Picture a healthcare technology company that has just deployed a generative AI assistant using Amazon Bedrock to help clinical staff summarize patient records. The product is technically functional, but the CISO raises a red flag: “We have no documented AI risk management process, no model transparency controls, and nothing showing human oversight is built in.” Enter the ISO/IEC 42001:2023 on AWS guide. The Solutions Architect and Security Engineer use it to map their Bedrock implementation to standard clauses — enabling AWS CloudTrail for model invocation logging, using AWS Config rules to enforce guardrails, and documenting human review workflows as part of the AIMS. Within weeks, the team will have a defensible governance posture they can present to regulators, auditors, and executive leadership. This is exactly the kind of scenario that appears in professional-level exam case studies — and exactly the kind of work enterprises need practitioners who can execute.
Why Cloud Professionals Should Add AI Governance to Their Skill Set Now
The integration of AI into cloud architecture is no longer optional for most enterprises, and neither is the governance layer that surrounds it. Compliance frameworks like ISO/IEC 42001 are moving from “nice to have” to “required before deployment” in many organizations, particularly those operating across international jurisdictions. Cloud professionals who can speak the language of AI risk management and translate it into AWS service configurations will hold a significant advantage in job roles ranging from Solutions Architects to AI/ML Engineers to Cloud Security Consultants. AWS publishing this guide is a strong signal that AI governance knowledge will increasingly appear in updated exam blueprints and job descriptions. Now is the time to get ahead of that curve, not catch up to it.
Closing: Turn Compliance Knowledge Into Career Currency
Understanding frameworks like ISO/IEC 42001 and how AWS operationalizes them is exactly the kind of depth that separates good cloud and AI practitioners from exceptional ones. At Tech Reformers, we bring real-world context to the official AWS curriculum — helping you connect compliance concepts like these to hands-on labs, real architecture scenarios, and the exam domains that matter most. Whether you’re preparing for your next AWS certification or leveling up your enterprise cloud skills, we’re here to help you build knowledge that transfers directly to the job.
👉 Explore our upcoming training programs at https://techreformers.com — and follow us so you never miss an announcement that could impact your certification journey or your career.
Your business runs on software. AI Development is the key to moving forward.
That’s why the pressure to ship faster without compromising quality, security, or compliance has never been higher. A Harvard Business Review Analytic Services white paper, sponsored by AWS, lays out exactly how high-performing engineering organizations are meeting that challenge.
The report calls out four interrelated pillars of modern software development. Get them right, and you innovate. Get them wrong, and you accumulate legacy debt that will slow you down for years.
Here’s the distilled version for engineering leaders — plus a path to upskill your team on AWS.
Forrester analyst Diego Lo Giudice frames it bluntly: software is how your business expresses itself. Every process, policy, and service runs through it.
By 2028, Forrester expects software delivery to look radically different — teams building applications at speeds that seem impossible today. The organizations that get there will be the ones that redesign their entire pipeline, not just their code editor.
The four pillars that get you there:
Speed and agility
Visibility through testing and observability
AI-powered development agents and automation
Embedded security and governance
Let’s break them down.
Pillar 1: Speed and Agility
Traditional waterfall development is dead and has been since Agile and DevOps took over. Development leaders already know this, but the execution gap is real.
AT&T’s Brian Hinshaw shared a telling data point in the report. Before modernizing, his team shipped one or two apps a year. After embracing modern practices — microservices, low-code platforms, and DevOps — productivity exploded to 60 or 70 apps per quarter.
That’s not a typo. That’s a 100x throughput improvement.
How? A combination of:
Microservices architecture that decouples deployment from monoliths
Automated CI/CD pipelines for frequent, reliable releases
Agile methodology paired with DevOps tooling (Accenture’s Adam Burden notes you can’t really do one without the other)
According to the Continuous Delivery Foundation, 83% of developers are already involved in DevOps activities. If your team isn’t, you’re already way behind.
Pillar 2: Improved Visibility Through Observability
Monitoring is not observability. That distinction matters more every year.
Capital Group’s Shawn Landreth describes joining a company that operated on a “distress protocol” — fix it after customers complain. A decade ago, that might have worked when systems were monolithic and had three layers. Today’s microservices architectures make that approach dangerous.
His team rebuilt around observability: predictive analytics on historical data, AI-driven noise reduction, and cross-functional operational calls that pull desktop support, help desk, and engineering into the same conversation.
The result? They cut 13,000 daily alerts down to under 1,000. Still a lot — but now actionable.
Pillar 3: AI-Powered Agents Automation
This is the pillar that’s changing fastest. Coding agents are changing the landscape!
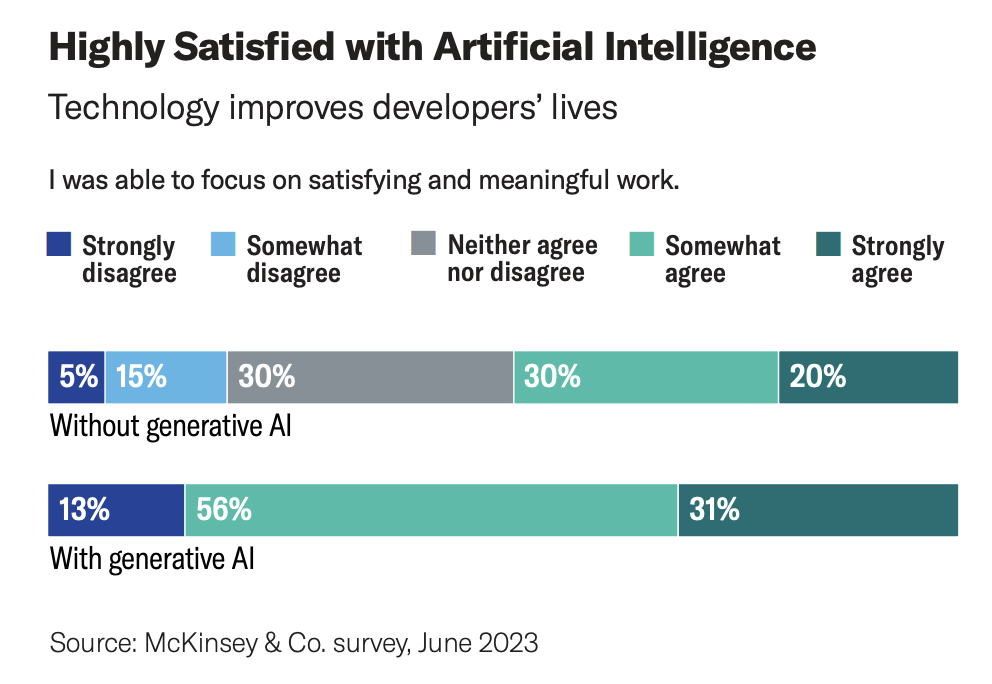
A McKinsey study found that 87% of developers using generative AI reported being able to focus on meaningful work — compared to just 50% of developers without it. That’s a massive quality-of-work gap, and it translates directly into retention and velocity.
Where is AI actually delivering? The HBR report highlights:
Code generation — natural language to working functions
Test case generation and defect prediction — Boston Consulting Group is embedding this into their QA process right now
Alert triage and root cause analysis — AI sitting in the middle of the observability stack
Predictive project analytics — forecasting delays before they happen
💡 The key insight: AI isn’t replacing developers. It’s absorbing the tedious work so humans can do the creative work. As you know, this study needs to look again for 2026 as coding agents are taking over. Our new article on Kiro and Claude Code will dive deep into using these with AWS. Of course, there are others and more keep popping up.
Pillar 4: Embedded Security and Governance
Speed without guardrails is how you end up in a breach notification.
U.S. Steel’s Adam Airhart inherited a decade of legacy systems with an unclear risk profile. His fix wasn’t dramatic. He started with version control on an AI-powered platform, then added build-and-release pipelines, and then added approval gates at every critical transition.
Developers got instant feedback. Security became part of the flow instead of a gate at the end.
This is the DevSecOps model, and it’s non-negotiable for regulated industries. HealthTech and FinTech leaders especially feel this — compliance isn’t optional, and bolting it on after the fact costs 10x more than building it in.
Accenture’s Burden warns against both extremes: too strict, and you kill innovation, too loose, and you build future technical debt. The companies that win have strong central governance paired with architects who can translate policy into developer-friendly guardrails.
The Skills Gap Is the Real Bottleneck
Here’s the uncomfortable truth. The pillars are well understood. The tooling exists. AWS provides the services.
What’s missing at most organizations is a team trained to actually execute.
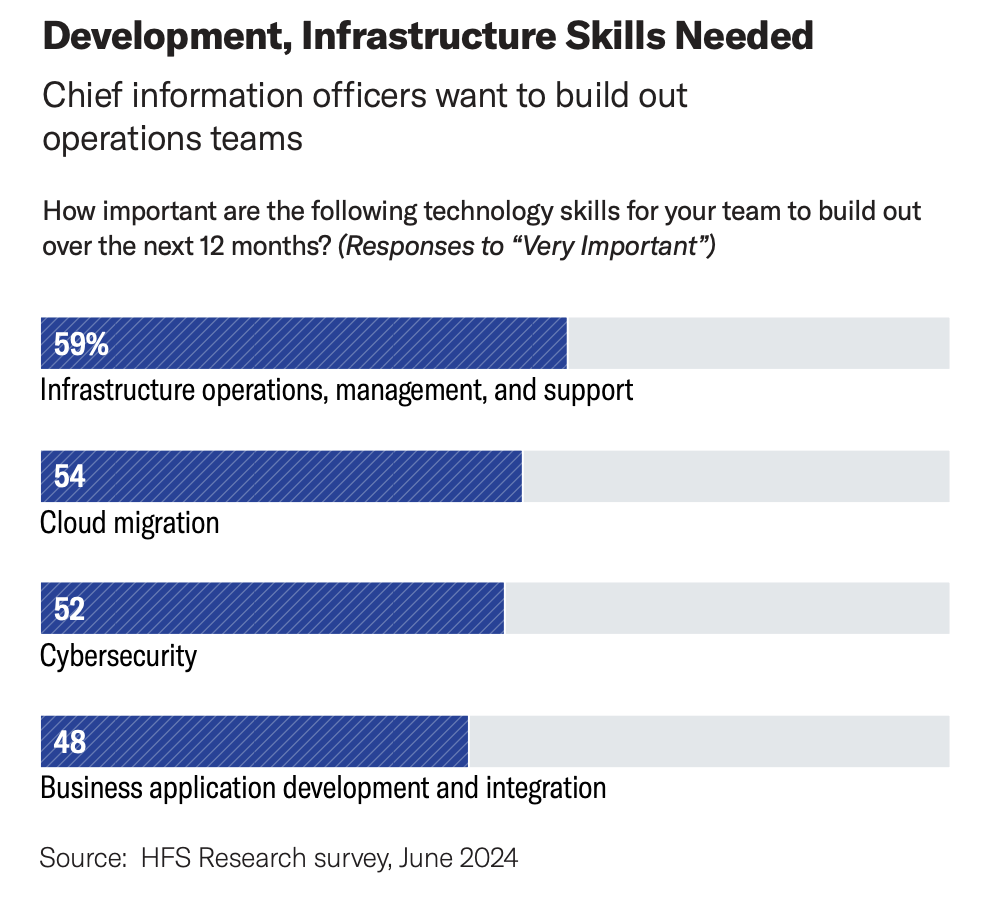
HFS Research found that 59% of CIOs rate infrastructure operations skills as “very important” to build out in the next 12 months. Cloud migration, cybersecurity, and business application development follow close behind.
If you’re an engineering leader, you have two options: wait for the market to solve your hiring problem, or upskill the team you have.
Two Training Paths to Get Your Team There
Tech Reformers is an AWS Authorized Training Provider and AWS AI Champion. We built our curriculum around the exact pillars HBR identifies.
This is the foundational course for experienced developers moving workloads to AWS. Your team will build a full cloud application — IAM permissions, S3 and DynamoDB integration, Lambda functions, API Gateway, Cognito authentication, and X-Ray observability. DevOps practices are embedded throughout.
It directly addresses Pillars 1, 2, and 4. Microservices, serverless, observability, and security patterns are all hands-on.
This is Pillar 3, operationalized. Your team will build production-ready generative AI solutions on AWS — foundation model selection, vector databases with Amazon Bedrock Knowledge Bases, prompt governance, agentic AI with AgentCore, AI safety guardrails, and cost optimization.
This is the course for teams that have moved past ChatGPT experiments and need to ship enterprise-grade AI with real governance.
Advanced level.
Change Is the Only Certainty
Lo Giudice closes the HBR report with a line that should be taped to every engineering leader’s monitor: “Agile transformation is a process that never ends.”
Three years ago, nobody predicted ChatGPT would redefine software development. Three years from now, something else will.
Your modern software practices need to be ready for anything — because change itself is the only constant.
Local governments sit on a mountain of public information including municipal codes, ordinances, permitting requirements, and service guides. Yet, hardly anyone can find information they want. Residents call city hall to ask questions that are already answered in a public document. Staff spend time answering the same questions over and over. The information exists; it just isn’t accessible.
Civic AI Agent is our answer. It’s a conversational assistant that lets residents ask questions and get accurate, cited answers drawn directly from official city documents with no hallucinations, no guessing, no dead-end search results.
We recently built a proof of concept for the City of Ruston. The architecture is designed to be replicated for any city, school district, county agency, or public organization.
What IsCivic AI Agent?
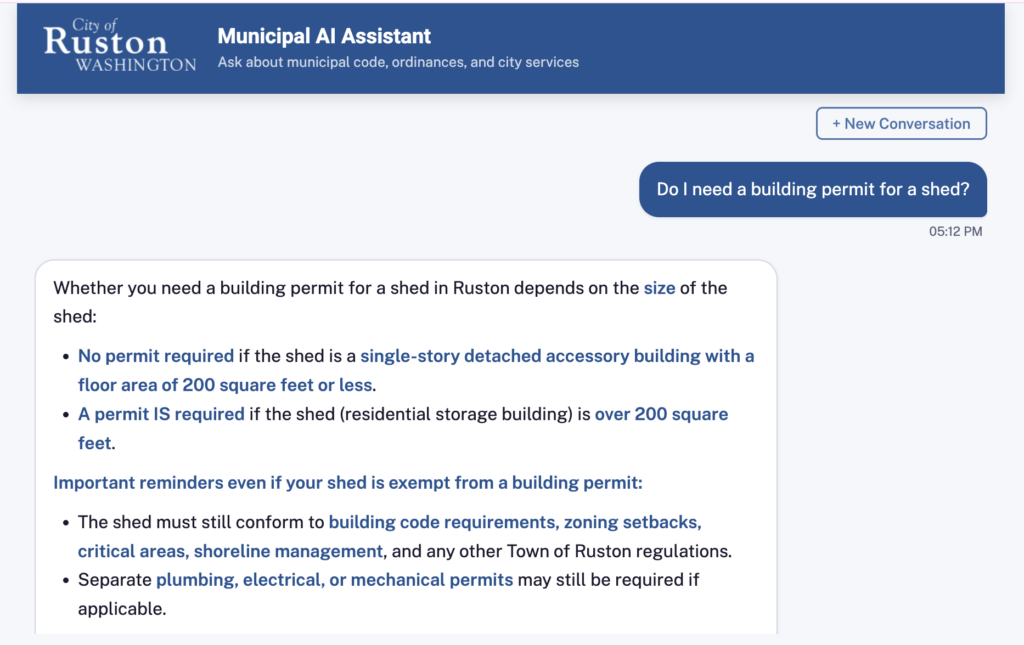
Civic AI Agent is a web-based chat interface built on AWS serverless architecture. Residents type a question like “What are the noise ordinance rules for construction?” or “How do I apply for a home occupation permit?” and receive a grounded answer with citations linking back to the exact section of the municipal code or ordinance that supports it.
The system is not a general-purpose chatbot. It only answers from documents you have explicitly indexed. That means every answer is traceable, auditable, and grounded in official city content.
Who Is It For?
Cities and municipalities with municipal code, ordinances, city services, permitting
School districts with policies, handbooks, enrollment requirements, board decisions
County agencies with zoning regulations, health codes, public records
Any organization with a large body of public-facing documents that residents or stakeholders need to navigate
Why an Agent? Not Just a Chatbot?
This is the most important architectural decision we made, and it shapes everything about where the product can go.
A chatbot answers questions. If you ask “How do I get a pet license?” it tells you the steps. That’s useful, but it’s still just a search engine with intelligent phrasing.
An AI agent can act. It has access to tools like APIs, forms, databases, external systems. Agents can execute multi-step workflows on your behalf. The difference looks like this:
Chatbot
Agent
“Here are the steps to apply for a pet license.”
“I’ve started your pet license application. Here’s what I need from you to complete it.”
“Your utility bill is due on the 15th.”
“I’ve scheduled your utility payment for the 14th. Here’s your confirmation.”
“The park permit form is at this link.”
“I’ve submitted your park reservation request for Saturday. You’ll receive a confirmation by email.”
Civic AI Agent is built on Amazon Bedrock Agents, which provides the orchestration layer that makes this possible. In its current form, the agent answers questions grounded in city documents. But because it is a true agent, not a chatbot, it can be extended with action groups that connect to permitting systems, payment processors, scheduling platforms, or any REST API the city exposes.
The foundation is already in place. Adding new capabilities is a matter of connecting new tools, not rebuilding the system.
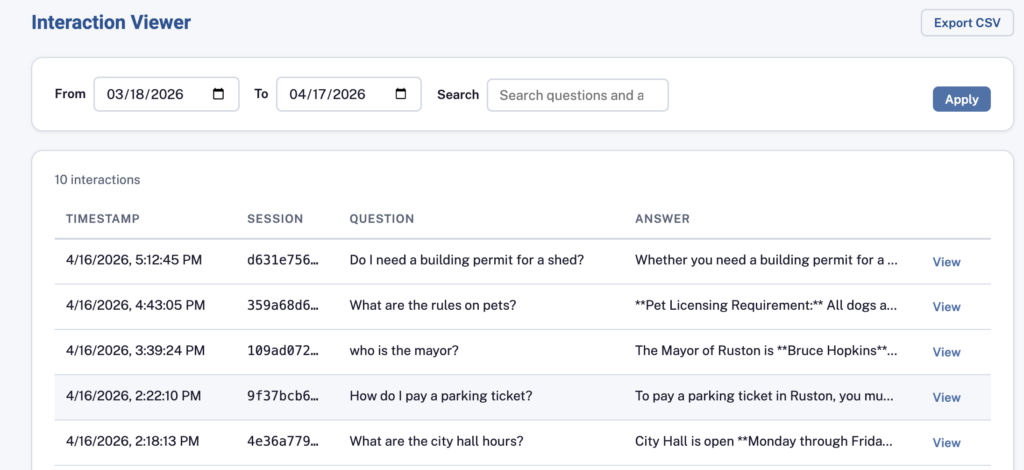
In Practice: The City of Ruston
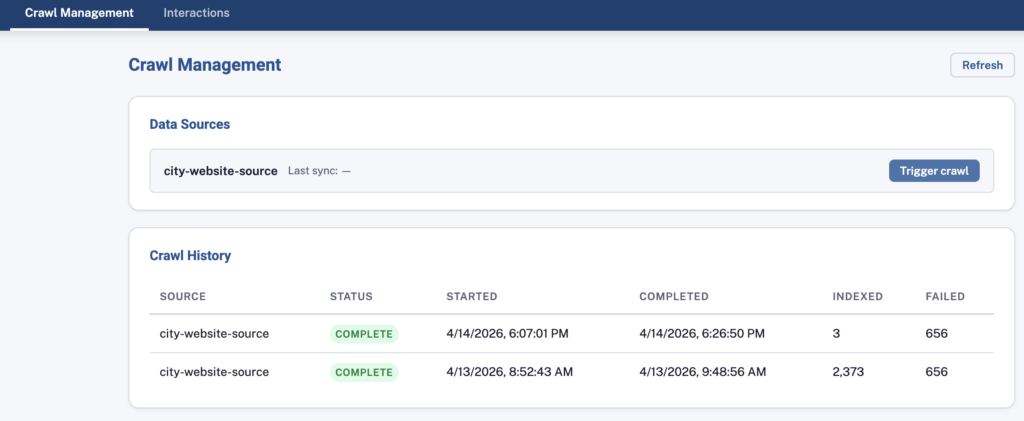
The City of Ruston proof of concept indexes the full municipal code and key pages from the city website. Residents ask questions and receive cited answers linked back to the source document. The City Clerk’s office manages the knowledge base, monitors resident interactions, and identifies documentation gaps through the admin portal — no engineering involvement required for day-to-day operations.
The proof of concept is the first deployment of the architecture. As it matures, we will share what we learn about resident usage patterns, the kinds of questions that surface documentation gaps, and how agent-based civic tools perform in a real municipal context.
Key Capabilities
Natural Language Q&A with Source Citations
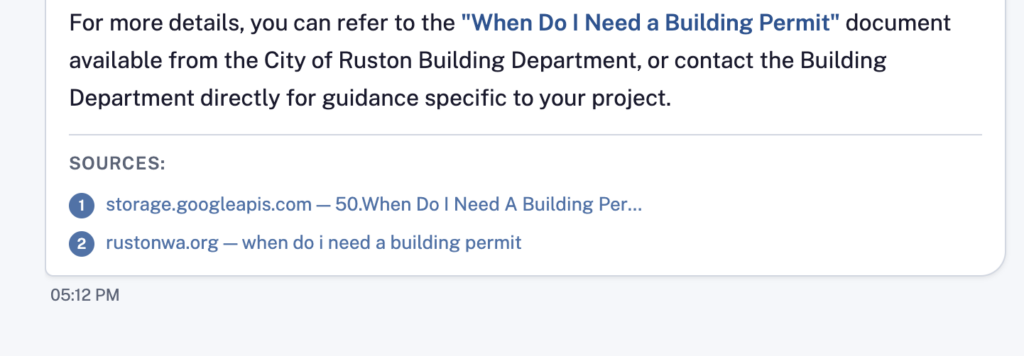
Residents ask questions the way they would ask a person. The agent retrieves the most relevant document chunks, synthesizes an answer, and cites the source including a direct link to the original document.
Retrieval-Augmented Generation (RAG)
Civic AI Agent uses the RAG pattern, the industry standard for grounded AI responses for internal resources. Rather than relying on a language model’s training data, every answer is assembled from documents you control. The model cannot fabricate information that isn’t in your knowledge base. We use Bedrock Knowledge Bases, which can crawl websites or point to specific knowledge stores.
Admin Portal with Knowledge Base Management
City Clerk’s staff manage the system through a secure admin portal. They can trigger crawls of city websites, monitor indexing jobs, and review every interaction residents have had with the assistant. No engineering involvement is required for day-to-day operations. They never need to use the AWS console to manage their data.
Interaction Analytics
Every question and answer is stored in a structured database. Administrators can browse and search all interactions to identify common resident questions, discover gaps in documentation, and improve city services.
All interactions pass through Amazon Bedrock Guardrails, which filter harmful content, block prompt injection, and keep responses within the scope you’ve defined, a non-negotiable for a public-facing agent representing the city.
AWS Serverless Architecture
Civic AI Agent is built entirely on AWS managed services. There are no servers to patch, no infrastructure to capacity-plan, and no operational overhead beyond the application itself. It scales automatically from zero to thousands of concurrent users.
Infrastructure as Code with AWS CDK
Every resource in the system, Lambda functions, API Gateway stages, DynamoDB tables, Cognito user pools, CloudWatch alarms, is defined in code using AWS Cloud Development Kit (CDK). There is no manual console configuration. The entire infrastructure can be deployed from scratch with a single command.
CDK lets us write infrastructure in TypeScript, the same language the team already knows. Constructs are composable, type-safe, and version-controlled alongside the application code. When a new customer needs a deployment, the template is forked, a configuration file is updated, and `cdk deploy` stands up a complete, production-ready environment.
This approach means:
Repeatability – every deployment is identical; no manual steps that can be forgotten or misconfigured
Auditability – infrastructure changes go through code review, just like application code
Teachability – new engineers can read the CDK stacks and understand exactly what is deployed and why
One Resource Per Layer — Environment Isolation Without Duplication
Rather than deploying entirely separate infrastructure stacks for dev and prod, each AWS service provides its own isolation mechanism:
Bedrock Agents: One agent with two aliases — a draft alias routes to the in-development version (dev), a pinned alias routes to the stable promoted version (prod)
Lambda: One function per handler with `dev` and `prod` aliases — the dev alias always tracks the latest version; the prod alias is explicitly promoted after testing
API Gateway: One REST API with `dev` and `prod` stages — stage variables route each request to the matching Lambda alias at runtime, with no code duplication
Amplify: One app with `dev` and `prod` branches — the branch determines the environment automatically
DynamoDB / Cognito: Separate tables and user pools per environment — data and authentication isolation is required at these layers
One codebase. Two environments. No duplicated infrastructure stacks.
This pattern eliminates configuration drift between environments, reduces infrastructure cost, and mirrors exactly how AWS intends these services to be used.
Infrastructure changes (CDK stacks) follow the same review-and-promote pattern through AWS CodePipeline with an audit trail, approval gates, and a fully automated path from development code commit to production.
Observability Built In
Every deployment includes CloudWatch dashboards and alarms out of the box:
API Gateway request volume, error rates, and p99 latency
Lambda duration, error counts, and throttles
DynamoDB system health
AWS X-Ray distributed tracing for end-to-end request visibility
Why These Choices Matter
Every architectural decision in Civic AI Agent is defensible and teachable. We chose Amazon Bedrock Agents over building our own orchestration layer because the agent primitive is where AWS is investing. Guardrails, and knowledge base integration are first-class features, not glue code we have to maintain. We chose CDK over console configuration because infrastructure that only exists as clicks in a console can’t be code-reviewed, can’t be diffed, and can’t be reproduced from scratch — and that means your team doesn’t really own it. We chose aliases and stages over duplicated stacks because that is how AWS designed these services to support multiple environments.
For a technical buyer, this matters in two ways. First, nothing here is exotic. Any engineer fluent in AWS serverless patterns can read the CDK, understand the Bedrock Agents configuration, and extend the system. Second, every pattern in this build is one we teach in our instructor-led classes. When we hand this system to your team, they are not inheriting a black box. They are inheriting a reference implementation of the same patterns they will see in training.
AWS Well-Architected Framework Alignment
Civic AI Agent is built to the AWS Well-Architected Framework across all six pillars:
AWS Well-Architected Pillar
How We Address It
Operational Excellence
AWS CDK infrastructure as code, CI/CD via Amplify and CodePipeline, CloudWatch dashboards and alarms
Security
IAM least-privilege roles, Cognito MFA, Bedrock Guardrails, no hardcoded credentials
Reliability
Serverless and multi-AZ managed services
Performance Efficiency
Serverless auto-scaling and graceful error handling
Cost Optimization
Pay-per-request on Lambda, DynamoDB, and AI model invocation, no idle compute, shared resources across environments
The architecture is designed to be replicated. Each new customer gets their own AWS account with a full, independent deployment, not a shared multi-tenant system. That means complete data isolation, independent scaling, and no blast radius between customers. Because the entire stack is defined in CDK, standing up a new city is a matter of forking the template, updating a configuration file, and running cdk deploy. A new base environment is live in under an hour. The real work is defining your data sources and how you want your agents to work.
About Tech Reformers
Tech Reformers is an AWS Advanced Services Partner and AWS Authorized Training Partner (ATP). We design and build cloud-native solutions on AWS, and we train the developers who build and the DevOps engineers who maintain them.
Civic AI Agent is both a production product and a reference implementation, every architectural decision demonstrates the AWS patterns our instructors teach in the classroom. When we hand a project to a client’s engineering team, they receive working code and the training to own it.
If you’re a city, school district, or public agency interested in deploying Civic AI Agent, contact us. If you’re an engineering organization looking to upskill your team on AWS serverless and generative AI patterns, see our upcoming instructor-led training.
Amazon Bedrock Now Ties AI Cost to IAM Users and Roles
Generative AI workloads are exciting — until the AWS bill arrives and no one knows who spent what. Amazon Bedrock’s new support for IAM principal-based cost allocation solves one of the most practical pain points in enterprise AI adoption: cost visibility and attribution. With this update, organizations can connect Bedrock model inference spending directly to the IAM users and roles making those calls. It’s a quiet but powerful addition that sits at the intersection of FinOps, identity management, and generative AI governance. For certification candidates and working cloud professionals alike, this is the kind of feature that shows up in exam scenarios and architecture reviews.
What Changed and How It Works
Previously, understanding which teams or applications were driving Amazon Bedrock inference costs required custom logging workarounds or third-party tooling. Now, AWS has built this capability natively into AWS Cost and Usage Report 2.0 (CUR 2.0) and Cost Explorer. The mechanism is straightforward: tag your IAM users and roles with meaningful attributes — such as team, project, or cost center — then activate those as cost allocation tags in the Billing and Cost Management console. From there, you either enable “Include caller identity (IAM principal) allocation data” when setting up a CUR 2.0 data export, or filter directly by those tags inside Cost Explorer. The result is granular, auditable cost attribution for every Bedrock inference call made under those principals.
Why This Matters for AI Cost Management
Cost optimization is not a nice-to-have in enterprise cloud design — it is a core pillar of the AWS Well-Architected Framework, and Solutions Architects are expected to design for it from day one. This feature gives architects a native mechanism to enforce cost accountability without building custom pipelines. For CloudOps engineers managing shared environments, this means the end of reactive cost conversations in which no one can identify the source of a spike. Tagging IAM roles by application or team is already standard practice in resource management, and this update extends that discipline to AI inference workloads. Operationally, it also creates a clean paper trail for chargebacks, budget approvals, and financial reporting across business units.
A Real-World Scenario Worth Walking Through
Imagine a financial services company running three internal Bedrock-powered tools: a document summarizer for the legal team, a customer email assistant for support, and a risk analysis copilot for the trading desk. Each application uses a separate IAM role. Before this update, Bedrock costs appeared as a single undifferentiated line item — frustrating for both engineering and finance. With IAM principal cost allocation enabled, the CloudOps team tags each role with the appropriate cost center and activates those tags in billing. Now the monthly CUR 2.0 report shows exactly how much each application consumed, down to the model and the time period. Finance can allocate costs accurately, leadership can make informed build-versus-buy decisions, and engineers can optimize the highest-cost workloads first.
The Certification Angle You Should Not Ignore
This feature is directly relevant to several AWS certification exams, and candidates should treat it as a test-worthy concept. The Solutions Architect Associate and Professional exams both emphasize cost optimization, tagging strategies, and the use of Cost Explorer and CUR for attribution — all of which appear here. For anyone studying these certifications, the ability to explain why IAM tagging supports financial governance in a multi-team AI environment is exactly the kind of scenario-based reasoning those exams reward.
At TechReformers, we bring announcements like this to life with real-world labs, demos, and scenario walkthroughs that go well beyond the slide deck. Whether you are preparing for a certification or building enterprise AI infrastructure, we help you connect the dots between AWS features and actual business outcomes. Visit us at 🔗 https://techreformers.com to explore our training programs and stay ahead of what AWS is shipping.
The cloud security conversation just expanded beyond IAM policies and S3 bucket permissions. AWS has published four core security principles aimed specifically at agentic AI systems. And if you work in cloud architecture, security, or AI development, this framework belongs in your professional toolkit. Agentic AI doesn’t just generate text. Now it reasons, plans, and takes action by connecting to APIs, tools, and live data sources. That autonomy is powerful, but it introduces attack surfaces and risk vectors that most cloud professionals haven’t had to think about before. Understanding these principles isn’t optional anymore. It’s becoming a core competency for anyone building or securing modern cloud workloads. Whether you’re preparing for a certification or architecting production systems, this is the kind of foundational shift worth understanding deeply.
What Makes Agentic AI Different From Everything That Came Before
To understand why new security principles are needed, you first have to appreciate what makes agentic AI fundamentally different. Traditional software executes predictable, hardcoded instructions. The security model is relatively contained. Generative AI advanced things by responding to natural language prompts, but humans remained in the loop, reviewing outputs before any action was taken. Agentic AI removes that human checkpoint. The model itself plans sequences of actions, selects tools, calls APIs, and executes workflows with varying degrees of autonomy.
Amazon Bedrock AgentCore is an agentic platform for building, deploying, and operating effective agents securely at scale—no infrastructure management needed.
or an overly permissive IAM role attached to an agent
can have cascading real-world consequences. The blast radius of a security failure in an agentic system is categorically larger than in prior AI paradigms.
Where to Start
The Agentic AI Security Scoping Matrix helps organizations calibrate the rigor of these controls based on their system’s level of autonomy. Scopes range from systems that require explicit human approval for every action to fully autonomous systems that initiate their own actions in response to external events.
The Four Security Principles for Agentic AI
AWS has outlined four principles that should guide the design and operation of agentic AI systems. The principles center on themes that experienced cloud professionals will recognize:
least privilege access,
strong identity and authentication boundaries,
input and output validation (including protection against prompt injection), and
maintaining human oversight at meaningful decision points.
What’s significant here is that AWS is applying classic security thinking, the kind baked into the Well-Architected Framework’s Security Pillar, to an entirely new category of workloads. These aren’t abstract ideas; they map directly to how you configure Amazon Bedrock Agents, what permissions you assign to Lambda functions invoked by agents, and how you design guardrails using Amazon Bedrock Guardrails. The principles are designed to be practical and implementable today, not aspirational guidance for a future state.
Real-World Scenario: Securing a Bedrock Agentic AI
Picture a financial services company deploying an Amazon Bedrock Agent to help relationship managers retrieve account summaries, flag compliance issues, and initiate document requests. Without proper security design, that agent could be manipulated via prompt injection to retrieve data outside its intended scope, or an over-permissioned tool connection could expose sensitive customer records.
Applying AWS’s four principles,
The architect would enforce least privilege on every API action the agent can invoke,
Implement input validation to detect and block adversarial prompt patterns, and require human confirmation before the agent triggers any financial transaction.
Amazon Bedrock Guardrails would be configured to filter outputs and restrict topic scope, and
AWS CloudTrail would log every agent action for audit and incident response purposes. This is exactly the kind of design decision that separates a secure AI deployment from a headline-making breach.
Certification Domains and Job Roles This Directly Supports
This content sits at the intersection of several high-value certification domains. Candidates preparing for the AWS Security Specialty will find this directly relevant to threat modeling, least privilege design, and data protection strategy — all of which now need to account for agentic workloads.
The AWS AI Practitioner exam covers responsible AI and foundational AI security concepts that reinforce these principles. Solutions Architect Professional candidates working through advanced security architecture and the Well-Architected Framework will also find this material applicable.
From a job-role perspective, Cloud Security Engineers, Gen AI Developers, and Solutions Architects are the professionals most immediately affected — but CloudOps engineers responsible for monitoring and incident response for AI-driven workloads need this context too. As agentic AI moves from pilot to production, this knowledge will appear in job descriptions and interviews, not just exam questions.
Why This Is the Right Time to Build These Agentic AI Security Skills
AWS publishing formal security principles for agentic AI is a strong signal that this architecture pattern is moving into mainstream enterprise adoption. Organizations that start applying these principles now. For certification candidates, getting ahead of emerging exam domains while they are still fresh gives you a meaningful advantage in both the test and in conversations with hiring managers. For enterprise practitioners, the cost of retrofitting security into an agentic AI system after deployment is always higher than building it in from day one. AWS has done the hard work of distilling these principles from real-world experience — the opportunity now is to apply them with confidence and depth.
At TechReformers, we’re an AWS Authorized Training Partner, and we build real-world context and hands-on labs around exactly this kind of emerging content — so that when it shows up on your exam or in your next architecture review, you’re ready. Whether you’re chasing your next AWS certification or hardening your organization’s AI workloads, we’re here to help you connect the dots.
What CloudFront, Security Hub, and Bedrock AgentCore Mean for Your AWS Career
Observability used to be something you configured. Now, with expanding auto-enablement in Amazon CloudWatch, it is something you govern. AWS has added three significant resource types to CloudWatch’s automatic telemetry configuration capability. If you are pursuing AWS certification or working in cloud operations today, this announcement deserves your full attention. It touches monitoring architecture, security posture management, and generative AI observability all at once. Understanding this feature is not just about keeping up with AWS news. Instead, it is about understanding how modern, scalable cloud architectures actually work.
—
What Auto-Enablement in CloudWatch Actually Does
Before this expansion, setting up logging and telemetry for resources such as CloudFront distributions often required manual per-resource configuration or custom automation scripts. CloudWatch’s auto-enablement capability introduced the concept of enablement rules. These are policies that tell AWS to automatically configure telemetry for existing and newly created resources without human intervention. Think of it less as a toggle and more as a standing order. Any resource that matches the rule has monitoring turned on automatically. This is a foundational shift from a reactive logging setup to proactive, policy-driven observability.
The Three New Resource Types and Why They Matter
The expansion covers three distinct areas of the AWS ecosystem. First, Amazon CloudFront Standard access logs can now be automatically routed to CloudWatch Logs using organization-wide enablement rules. Consequently, it makes consistent CDN visibility available across every account in an AWS Organization without manual distribution-level configuration. Second, AWS Security Hub CSPM (Cloud Security Posture Management) finding logs now support the same organization-wide scope. As a result, security teams can automatically aggregate posture findings into CloudWatch without building custom pipelines. Third, Amazon Bedrock AgentCore memory, gateway logs, and traces are now supported at the account level. All this give AI developers automatic observability into their agent-based applications from the moment those resources are created.
Governance at Scale: Organizations, Accounts, and Tags
One of the most exam-relevant concepts in this announcement is the scoping model for enablement rules. Apply rules at three levels: across an entire AWS Organization, to specific accounts, or to specific resources identified by resource tags. This aligns directly with AWS best practices for multi-account architecture and with governance frameworks such as AWS Control Tower and AWS Organizations. A central security team can define a single rule that cascades CloudFront access logs and Security Hub findings to CloudWatch across every account. For certification candidates studying governance, multi-account strategies, and least-privilege automation, this is a concrete, real-world example of policy-as-configuration.
A Real-World Scenario: The Enterprise Security Team Use Case
Imagine a global e-commerce company running hundreds of CloudFront distributions across a multi-account AWS Organization. Their security operations team needs to ensure that every distribution’s access logs are captured and searchable for incident response and compliance auditing. Before auto-enablement rules, this meant either onboarding scripts, manual configuration per account, or relying on developers remembering to enable logging at deploy time. All of these options create gaps. With a single org-wide CloudWatch enablement rule, every CloudFront distribution — existing ones and every new one created going forward — automatically sends logs to CloudWatch Logs. Pair that with a Security Hub CSPM enablement rule. As a result, the security team now has a unified, automatically populated observability layer with no ongoing maintenance overhead.
Certification Exams and Job Roles This Directly Supports
This announcement is relevant across multiple certification tracks. Candidates preparing for the AWS Certified Solutions Architect – Associate and AWS Certified Solutions Architect – Professional exams should note the governance, multi-account design, and monitoring architecture angles. The AWS Certified Cloud Practitioner exam tests foundational understanding of CloudWatch’s role in monitoring and compliance, and this feature reinforces that knowledge. For the AWS Certified AI Practitioner, the Bedrock AgentCore telemetry component introduces an observability dimension to generative AI workloads that is increasingly appearing in AI-focused learning paths. From a job role perspective, CloudOps engineers, cloud security engineers, and solutions architects working in regulated industries or enterprise environments will find this feature immediately applicable. If your organization runs any meaningful CloudFront footprint or is maturing its generative AI operations, this capability belongs in your architecture toolkit now.
Start Building with These Concepts Today
AWS continues to raise the bar on what automated, policy-driven observability looks like at enterprise scale. CloudWatch auto-enablement rules are not a minor quality-of-life update. Instead, they represent a meaningful architectural capability that exam writers, hiring managers, and cloud architects all care about. Understanding how to scope these rules, which resource types they support, and how they interact with AWS Organizations is the kind of nuanced knowledge that separates certified professionals who passed a test from practitioners who can design production systems. At TechReformers, we bring these announcements to life through real-world context, hands-on labs, and demos built around the official AWS curriculum. Visit us at https://techreformers.com to explore our upcoming training, stay ahead of announcements like this one, and build the skills that actually move your career forward.
The compliance question that keeps security teams up at night has always been: “How do I know everything is actually encrypted?” Not theoretically encrypted. Not encrypted-most-of-the-time. Actually, provably, audit-ready encrypted. And encrypted across every network path, every load balancer, every container workload. AWS just made that question a lot easier to answer. With the launch of VPC Encryption Controls in AWS GovCloud (US-East) and GovCloud (US-West), teams can now monitor, enforce, and demonstrate encryption in transit across their entire VPC footprint with a few clicks. For anyone studying AWS certifications or working in regulated industries, this is a capability shift worth understanding deeply. Let’s break it down.
What Are VPC Encryption Controls
AWS has long provided hardware-based AES-256 encryption transparently between modern EC2 Nitro instances, across Availability Zones, and across Regions for inter-region traffic using VPC Peering, Transit Gateway Peering, and AWS Cloud WAN. The encryption was there, but visibility was not. Before this feature, confirming that every network path was actually encrypted required manual investigation and custom tooling. Additionally, it required a lot of trust. VPC Encryption Controls changes that by giving you a centralized control plane to monitor the encryption status of all traffic flows. You can identify VPC resources that unintentionally allow plaintext traffic and automatically enforce encryption. It also generates audit logs, which compliance officers have been asking for since practically forever.
What Gets Encrypted and How?
The encryption itself is hardware-based AES-256, applied transparently — meaning your applications do not need to change. VPC Encryption Controls extends this enforcement to traffic involving AWS Fargate, Network Load Balancers, and Application Load Balancers. This is in addition to EC2 Nitro instance traffic already covered. The “transparent” part is critical here: this is not application-layer TLS that you configure in your code or in your load balancer listener. This is a network-layer, hardware-accelerated encryption layer that AWS applies automatically once you enable enforcement mode. For multi-VPC architectures, this means you can enforce consistent encryption standards across complex topologies without coordinating changes across dozens of application teams.
Why GovCloud and Why Does It Matter for Compliance?
GovCloud regions exist specifically to support US government workloads and the compliance frameworks that come with them — FedRAMP, HIPAA, PCI DSS, FIPS 140-2, and others. These frameworks do not just require encryption; they require evidence of encryption. The ability to generate audit logs that demonstrate encryption in transit across all VPC traffic paths is not a nice-to-have in these environments — it is a certification requirement. Before VPC Encryption Controls, customers had to assemble this evidence from fragmented sources, which introduced audit risk and significant operational overhead. Now, your information security team can enable the feature centrally and set enforcement policies. They can also produce clean audit logs on demand. For any organization pursuing or maintaining a FedRAMP Authorization to Operate (ATO), this is a meaningful operational simplification.
Real-World Scenario: A Federal Contractor’s Compliance Sprint
Imagine a cloud engineering team at a federal contractor running a multi-tier application in GovCloud. They have EC2 Nitro-based application servers, containerized microservices on Fargate, and traffic flowing through both an Application Load Balancer and a Network Load Balancer. Ahead of an annual FedRAMP audit, their compliance officer asks for evidence that all intra-VPC and inter-VPC traffic is encrypted in transit. Previously, this meant pulling logs from multiple sources, cross-referencing instance types, and hoping nothing was missed. With VPC Encryption Controls enabled, the team can pull a single audit report showing encryption status across all traffic flows. They can identify a legacy EC2 instance type that was allowing plaintext traffic, remediate it, and hand the auditor a clean log — all before the audit kicks off. That is not a hypothetical; that is the exact use case AWS designed this feature for.
Certification Exam Implications — What You Need to Study
This feature directly supports learning objectives that appear across multiple AWS certification exams. For the AWS Certified Security Specialty exam, expect scenarios that test your knowledge of encryption-in-transit architecture, compliance framework requirements, audit log generation, and the difference between application-layer and network-layer encryption. The AWS Certified Solutions Architect Associate exam tests VPC design, data protection strategies, and the selection of appropriate encryption controls for different workloads. VPC Encryption Controls is a perfect case study. For professionals pursuing roles as Solutions Architects, CloudOps Engineers, or Security Engineers in government or regulated industries, understanding how to enable, configure, and interpret VPC Encryption Controls is quickly becoming both a practical job skill and an exam topic. If you are studying for any of these exams, add encryption-in-transit enforcement, AES-256 hardware encryption, and compliance audit logging to your active study list right now.
Start Learning This Before Your Exam — or Your Next Audit
AWS VPC Encryption Controls in GovCloud is one of those features that sits at the exact intersection of real-world urgency and exam relevance. It solves a genuine compliance pain point, and it introduces important architectural concepts. It is the kind of capability that will absolutely appear in scenario-based exam questions. At TechReformers, we help certification candidates and enterprise learners connect announcements like this one to the hands-on skills and exam knowledge that actually move careers forward. Whether you are preparing for a security certification or upskilling your team for regulated cloud environments, we have the labs, context, and expert instruction to get you there. Visit us at https://techreformers.com to explore our upcoming courses and get ahead of what AWS is building next.
On October 20, 2025, AWS (Amazon Web Services) experienced a significant outage that took down thousands of services worldwide. Snapchat, Venmo, Robinhood, Roblox, Fortnite, Ring, and Alexa all went dark because of the AWS outage, leaving millions of users unable to access critical services and applications.
At Tech Reformers, an AWS Advanced Services Partner and Authorized Training Provider, we were busy working with state and local agencies, K-12 schools, and businesses. During an outage like this, our communication channels start “ringing.” People were worried. They depend on services that run on AWS, and if AWS has problems, their work stops.
So let’s break down what happened, why it matters, and what you can do to be prepared.
What Caused the AWS Outage?
The trouble started at 3:11 AM ET in AWS’s us-east-1 region (Northern Virginia). Multiple services began showing higher error rates and increased latency. By 5:01 AM, AWS engineers identified the culprit: DNS resolution issues affecting the DynamoDB API endpoints. That is, the managed database system lost meaningful connectivity.
Understanding DNS
DNS (Domain Name System) deserves some explanation because it’s at the heart of this outage. DNS is essentially the internet’s address book—it translates human-readable names (like “dynamodb.us-east-1.amazonaws.com”) into the IP addresses that computers use to connect.
Here’s the critical part: DNS isn’t controlled by any single company. It’s a distributed service run by independent organizations and agencies worldwide. These DNS servers are deployed worldwide and need to be continually refreshed with updated information. When DNS breaks—as it did in this case—applications can’t find the services they need to connect to, even if those services are running perfectly fine.
In this case, DynamoDB—a core database service many applications depend on—became unreachable because DNS couldn’t resolve its endpoints. The problem required manual interventions to bypass faulty network components. Complete recovery was achieved by 1 PM ET, though some services experienced lingering slowness into the evening.
The AWS us-east-1 Outage Factor
Here’s what makes this outage particularly significant: us-east-1 is AWS’s largest region (and its first). It started in 2006, running the first three services—SQS, S3, and EC2. Perhaps because of this history, many AWS global services depend on us-east-1 for critical functions.
When us-east-1 has problems, workloads around the world can be affected even if their own regional infrastructure is running perfectly.
Services with Known us-east-1 Dependencies
Several AWS services have dependencies on us-east-1:
IAM and IAM Identify Center – Authentication and access management
DynamoDB Global Tables – Cross-region database replication and coordination
Sometimes you can’t avoid these dependencies. Instead, you need to build resilience around them.
Who Was Actually Affected?
Here’s what we’re hearing from our customers: their own infrastructure on AWS was fine. They were affected because services they depend on went down—Slack stopped working during critical meetings, payment systems couldn’t process transactions, and communication tools went silent. But they’re worried that next time, they could be affected.
The outage hit:
Financial Services: Robinhood and Coinbase couldn’t process transactions
E-commerce: Amazon.com itself went down, along with McDonald’s and Starbucks apps
Transportation: United Airlines and Delta reported delays
Government Services: Medicare’s enrollment portal stopped working
Collaboration Tools: Slack and other productivity apps slowed to a crawl
Gaming: Roblox, Fortnite, and Pokémon GO became unplayable
You can joke about some of these: Aren’t delays the norm from United and Delta? Well, did the gamers have to get to work? Maybe crypto- and day traders profited from holding anyway. But the outage is serious business.
For schools managing daily operations, agencies serving citizens, and businesses running critical workflows, these outages create real problems. When your collaboration tools go down, work stops. When your payment processor goes offline, revenue stops. When your communication systems fail, you can’t reach the people you need to reach.
Many of our customers are now asking: “What can we do about this? We’re vulnerable.”
That’s a fair question. Let’s talk about it.
Building Resilience: What You Can Actually Control
If you’re using SaaS applications that run on AWS, you have limited control over their infrastructure decisions. But you do control your infrastructure:
1. Deploy Multi-Region Architecture
Architect critical workloads to run in at least two geographically separated regions. Use Route 53 health checks and automatic failover to redirect traffic when problems occur.
Example configuration: Deploy your primary workload in us-west-2 (Oregon) and maintain a secondary deployment in us-west-1 (N. California). This geographic separation means different power grids, different network infrastructure, and reduced risk of correlated failures.
This isn’t necessary for everything. Focus on mission-critical workloads first – student information systems, file access, and business systems.
Avoid us-east-1 where possible.
2. Implement Standby Systems
Here’s where we need to talk about money because this is where organizations often hesitate.
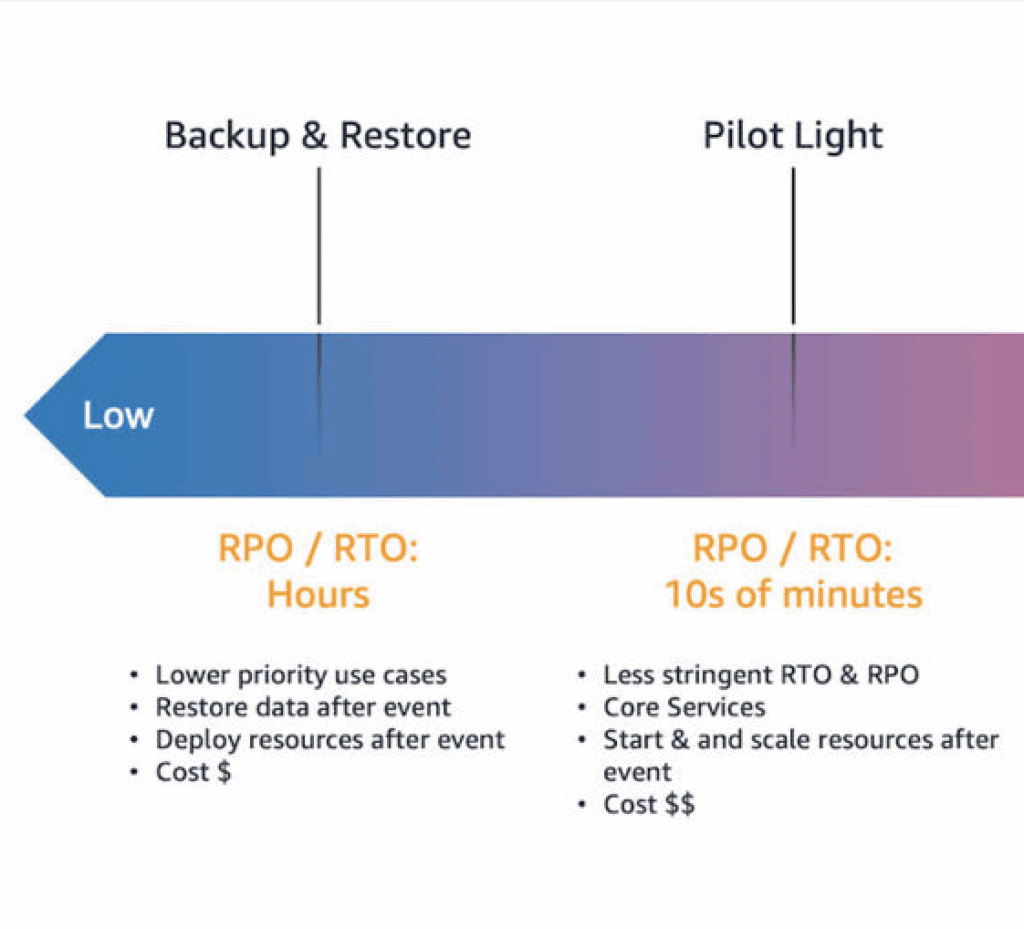
Backup and Restore: Cheapest option, but leaves you vulnerable during outages. Recovery takes hours or days. Cost: ~1-2% of primary infrastructure.
Pilot-Light: Set up in another region, not just a backup. The infrastructure is not running but up-to-date and ready to be turned on. Recovery takes minutes to hours. Cost: ~5-10% of primary infrastructure.
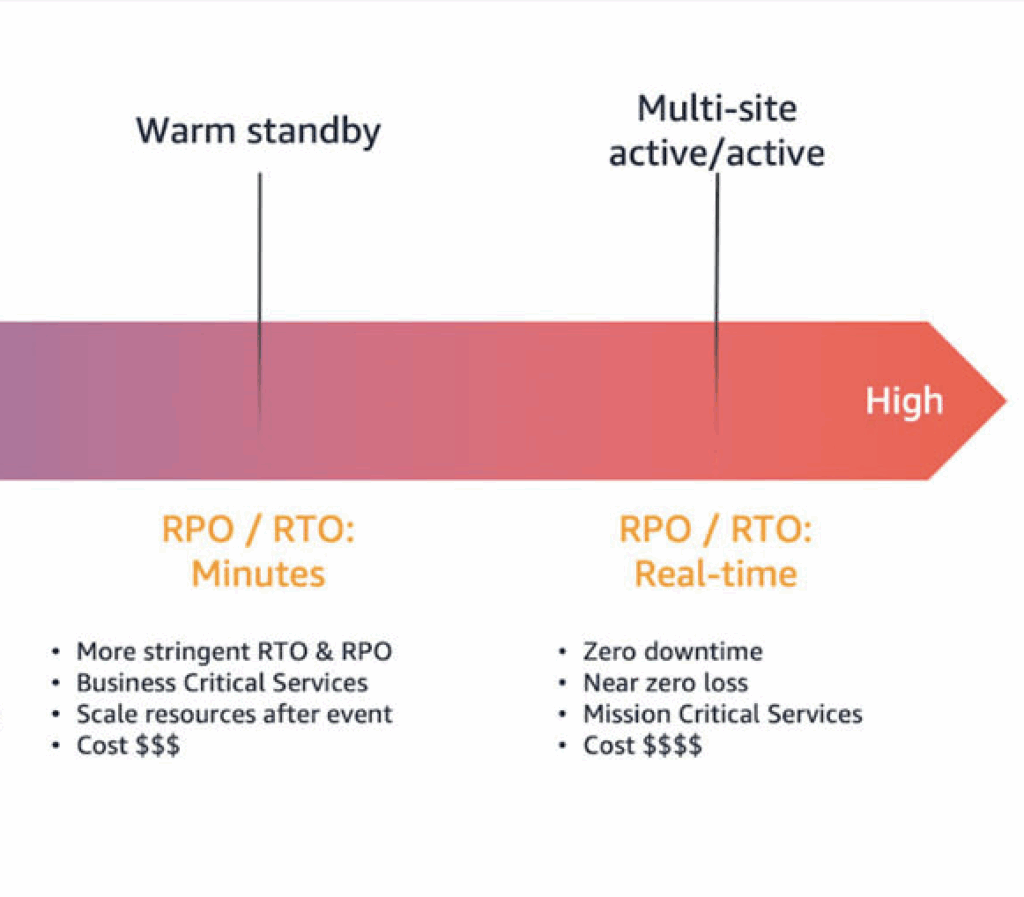
Warm Standby (scaled-down infrastructure ready to scale up): Middle ground. You run minimal infrastructure in a secondary region that can quickly scale when needed. Recovery takes minutes. Cost: 20-30% additional.
Multi-site Active/Active (production-scale infrastructure in multiple regions): Most expensive, fastest recovery. Traffic is actively distributed across regions. Recovery is essentially instant. Cost: Can double your infrastructure spending.
The Real Question: What does downtime cost you? AWS itself offers an excellent solution for cross-region replication: AWS Elastic Disaster Recovery. AWS offers four main disaster recovery (DR) strategies to create backups that remain available during disasters. Each strategy has a progressively higher cost and complexity, but lower recovery times.
For school districts facing deadlines, being down for three hours might mean missed deadlines and frustrated families. For a government agency processing critical permits, six hours of downtime could mean compliance violations. For businesses, money is lost when there are no orders. That’s the calculation you need to make.
We help our clients figure out which workloads justify the extra cost. Not everything needs standby, but your most critical systems probably do.
3. Build Resilience Around Dependencies You Can’t Avoid
You may not eliminate dependencies on services like IAM or CloudFront. But you can reduce your exposure:
Use regional service endpoints: Where AWS offers regional alternatives, use them. Not everything needs to route through global services.
Add an alternative to the Disaster Strategy: Something is better than nothing or errors. Have local or simplified versions of a working architecture.
4. Have Backup Communication Channels
This applies to everyone, whether or not you run AWS infrastructure. When your primary collaboration tools fail, how do you communicate?
Build redundancy into communications:
If Slack/Teams goes down, can your team switch to something else?
If your primary email provider fails, do you have phone trees in place?
Can you reach critical stakeholders through multiple channels?
This sounds basic, but we’ve seen organizations grind to a halt when their primary communication tool goes offline, with no backup plan.
5. Diversify Your Vendors
If possible, don’t put all your critical services on platforms that run on the same cloud provider or ecosystem. This isn’t always feasible, but where you have choices:
Use collaboration tools from different providers
Consider email/collaboration and data center infrastructure that run on different ecosystems
As they say, don’t have all your eggs in one basket
The challenge: many of the best services run on AWS because it’s the largest, most reliable platform.
6. Document and Test Your Workarounds
When services you depend on go down, what’s your plan?
Create documented workarounds:
If Teams fails, here’s how we switch to something else…
If our file server is down, here’s our process…
If our scheduling system fails, here’s our backup approach…
More importantly, test these workarounds—schedule drills. Time them. Make sure your team knows what to do before the emergency happens.
7. Practice Chaos Engineering—But Start with Drills First
Chaos engineering means intentionally breaking things to see how your systems respond. It’s valuable, but you need to walk before you run.
Phase 1: Scheduled Recovery Drills Run planned failover exercises during maintenance windows. Your team knows it’s coming, they follow the runbook, and you measure how long it takes. Do this until recovery becomes routine.
Phase 2: Unannounced Drills with Random Timing Once your team can execute recovery smoothly, start adding surprise elements—schedule drills at random times during business hours. Don’t tell the on-call person it’s coming. See if they can follow the runbook under pressure.
Phase 3: Fault Injection in Production Only after you’ve mastered phases 1 and 2 should you consider using AWS Fault Injection Simulator (FIS) to inject random failures into production systems. Test things like:
Regional connectivity failures
Database unavailability
API throttling scenarios
DNS resolution failures
The key is randomness. Real failures don’t happen during convenient maintenance windows. They happen at 3 AM or during your busiest hours. Your systems need to handle that.
Preparing for the Next AWS Outage: Action Steps
Document what happened during this outage if it affected you:
Which services did your organization rely on that went down?
How long were you unable to work effectively?
What was the business impact—missed deadlines, lost productivity, frustrated users?
What workarounds did people improvise?
What dependencies did you discover that you didn’t know existed?
Identify your critical dependencies: Make a list of the services your organization absolutely needs to function. For each one, find out:
Is it SaaS (managed service) or Cloud infrastructure you control?
Does it have built-in redundancy?
What’s their uptime SLA?
What’s your backup plan if it fails?
AWS Disaster Recovery
AWS is still the best cloud platform for most workloads despite this AWS outage. This outage doesn’t change that. But it reminds us that no system is immune to failure, and dependencies we don’t even think about can bring down services we rely on.
The question isn’t whether another outage will happen—it’s whether you’ll be ready when it does. Be prepared with an AWS disaster recovery plan.
How Tech Reformers Can Help
We’ve worked with schools, agencies, and businesses to build resilient AWS architectures and prepare for disruptions like this one. Our team includes certified AWS Architects and Engineers, as well as AWS Authorized Instructors, all with deep expertise across compute, storage, networking, security, and disaster recovery.
As an AWS Advanced Services Partner and Authorized Training Provider, we offer:
AWS Well-Architected Reviews: We assess your infrastructure against AWS best practices, with a specific focus on reliability and operational excellence. Where are your single points of failure? What’s your actual recovery capability? We’ll tell you.
Disaster Recovery Planning: We help you design and implement multi-region strategies based on realistic requirements and budget constraints. We’ll help you figure out which workloads need hot standby and which don’t.
Resilience Testing Workshops: Hands-on training for your teams on failover procedures, incident response, and building resilient architectures. We’ll help you design and run your first recovery drills.
AWS Training and Certification: Official AWS courses delivered by authorized instructors. Solutions Architect, SysOps Administrator, DevOps Engineer, Security Specialty—we teach them all, both virtual and in-person.
Consulting Services: We work with you on AWS implementations, migration planning, security architecture, and ongoing optimization. Many of our solutions are available on AWS Marketplace.
Ready to avoid an AWS outage and build more resilience into your organization? Contact us for a consultation. Whether you run your own AWS infrastructure or depend on services that do, we can help you prepare for the next disruption.
Leading AWS-focused services and training firm achieves milestone of AWS Advanced Tier Services Partner Status. Marked by successful client deployments and internal training and certification milestones, Tech Reformer met the challenge.
Advanced tier recognition validates Tech Reformers’ deep expertise in cloud migration and AI workloads for public sector, education, and SMB clients.
August 29, 2025 – Tech Reformers, a specialized Amazon Web Services (AWS) service and Authorized Training Provider, today announced it has achieved AWS Advanced Tier Services Partner status. This prestigious recognition acknowledges the company’s demonstrated expertise, successful customer outcomes, training, and commitment to AWS best practices across cloud migration and artificial intelligence implementations.
The Advanced Tier achievement reflects Tech Reformers’ significant investment in AWS expertise, with eight accredited professionals, including four technical and four business specialists. The company has also secured six AWS technical certifications, including three at the Professional or Specialty level, and four AWS Foundational certifications across its team. This milestone was reached through the successful delivery of over 20 launched opportunities, generating more than $10,000 in monthly recurring revenue.
Specialized Focus Drives Success
Unlike generic cloud providers, Tech Reformers maintains an exclusive focus on AWS services. This positions the company as a true specialist in Amazon’s cloud ecosystem. This concentrated expertise, combined with their status as an AWS Authorized Training Provider, creates a unique value proposition. For organizations seeking both implementation services and learning AWS, Tech Reformers “teaches them to fish.”
“Achieving AWS Advanced Tier Services Partner status validates our strategic decision to focus exclusively on AWS and our team’s dedication to mastering the platform’s capabilities,” said John Krull, President of Tech Reformers. “This recognition demonstrates our ability to deliver complex cloud migrations and AI workloads that drive real value for our clients in the public sector, K-12 education, and growing SMB markets. Our dual role as both a service partner and training provider allows us to implement not just solutions. We empower our clients with the knowledge they need to succeed long-term.”
Addressing Critical Market Needs
Tech Reformers specializes in serving three key market segments. First, K-12 districts seeking to modernize their technology infrastructure recognize the expertise of Tech Reformers. Next, public sector organizations navigating cloud adoption see Tech Reformers ability to move Microsoft workloads to AWS. Finally, small to medium-sized businesses taking their first steps into cloud and AI can learn from Tech Reformers’ experience. This focus allows the company to develop deep domain expertise and tailored approaches for each sector’s unique challenges and compliance requirements.
The company’s expertise in cloud migration helps organizations transition from legacy on-premises infrastructure to scalable, secure AWS environments. Additionally, their AI workload specialization positions clients to leverage machine learning, artificial intelligence, and data analytics capabilities. These can transform business operations and decision-making processes.
Comprehensive AWS Expertise
As an AWS Advanced Tier Services Partner, Tech Reformers brings proven capabilities across the full spectrum of AWS services. The company’s certified professionals possess deep technical knowledge in areas including:
Cloud Migration Services: End-to-end migration planning, execution, and optimization. Tech Reformers recently completed a migration of the Los Gatos Union School District.
AI and Machine Learning: Implementation of AWS AI services for business transformation. Tech Reformers has completed implementations of website AI chatbots, PDF accessibility ML pipeline, and enterprise data tools.
Security and Compliance: Robust security measures meeting public sector and educational requirements. All Tech Reformers clients get a secure landing zone with their AWS QuickStart.
Training and Knowledge Transfer: Official AWS training delivery as an Authorized Training Provider
Cost Optimization: Strategic guidance on maximizing cloud investment returns
Strong Foundation for Growth
The Advanced Tier achievement represents a significant milestone in Tech Reformers’ growth trajectory. AWS categorizes partners into tiers based on expertise, customer success, and service delivery standards, with the Advanced Tier representing a substantial commitment to AWS excellence. Partners must demonstrate technical competency, successful customer implementations, and ongoing investment in AWS capabilities.
AWS remains the world’s most comprehensive and widely adopted cloud platform, offering over 200 fully featured services from its global data centers. Millions of customers – including fast-growing startups, large enterprises, and government agencies – rely on AWS to reduce costs, increase agility, and accelerate innovation.
Looking Forward
With Advanced Tier status now secured, Tech Reformers is well-positioned to serve growing demand for specialized AWS expertise across its target markets. The company’s combination of deep technical capabilities, focused market approach, and training expertise creates a compelling value proposition for organizations seeking to maximize their AWS investments.
Organizations interested in learning more about Tech Reformers’ AWS capabilities can visit https://techreformers.com or contact their team directly to discuss cloud strategy and implementation needs.
About Tech Reformers
Tech Reformers is a specialized AWS services firm and Authorized Training Provider focused exclusively on Amazon Web Services implementations. The company serves public sector, education, and small-to-medium business clients with expertise in cloud migration and AI workloads. Founded on the principle that focused expertise delivers superior outcomes, Tech Reformers combines deep AWS knowledge with targeted market understanding to help organizations achieve their cloud transformation goals.
For more information about Tech Reformers and their AWS services, contact info@techreformers.com or call (+1 (206) 401-5530.





![DIAGRAM: Architecture overview — Amplify → API Gateway → Lambda → Bedrock Agent → Knowledge Base → DynamoDB]](https://techreformers.com/wp-content/uploads/2026/04/image-5-1024x722.png)